|
ANOTHER MAKEFILE REFACTOR You guys know I love spending a few hours refactoring a significant chunk of my code because I realize it's either severely overengineered or underengineered. Makefile is a software tool that basically automates the build process-- essentially how to turn my text into machine bytes that can be ran on hardware. Since my project constantly grows more dense and complex, having a functioning makefile is vital to testing my code. The problem was that my makefile is not scalable. It's very hard to add new changes or refactor my code architecture. So for a few days, I diagrammed out my new and improved makefile build pipeline to be more scalable. A lot of generality was introduced which could automatically deal with any changes I made to my code. This is a picture of my diagram, although I recommend downloading it to fully view all the steps. It could still be compressed and generalized even more, but for now this offers a great visual aid into how I add and refactor new things into my codebase. 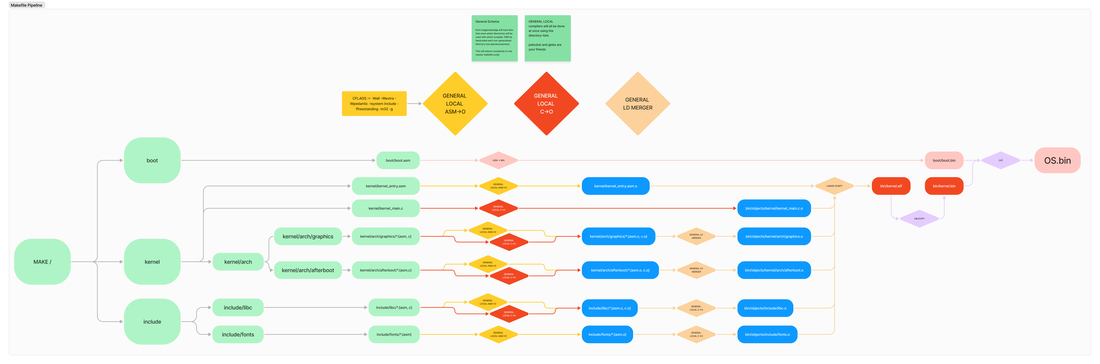 I then implemented it into my now very efficient and readable makefile and the build process was much more smooth. Stay tuned for updates about my designs for my shell language and window manager!
1 Comment
Hurrah!
This past month, I had been hard at work working, completing, and delivering upon my 50% summer goals presentation. A week later, in the second week of September, I received news of my Fellows status! From the 15th to now, I have been hard at work learning 3D modelling software and drafting up requisition forms for the EE section of my fellows project. I will soon upload an updated budget to my website. Stay tuned for some cool 3D models!  Nearing the End
As I come to a close in my project, I can see so much that has been accomplished in terms of the operating system and have nearly come to a close to the summer goals. So far, I have discussed with my mentor, Mr. Baraty, and have talked about the upcoming plans for the year and reevaluating and verifying my summer goals. Final Progress Before the Meeting I have already developed code that can establish interrupts, and I almost have a functioning keyboard driver. All the boilerplate assembly and tooling functions are in place. All in need to do is program the PIC and write the actual driver. Once the keyboard driver is done, I basically am 99% done with my goals for the summer. The rudimentary shell will be very basic, since not much will need to be done until more specifications come out way later. Also with the schematics and the engineering, I have a very solid idea of my approach and plan into making this into a tangible, held-able thing. Thoughts on the 50% OS Goal I think I may have actually overstepped the 50% mark for the OS side. Most of the core components are done in the OS. The ones that are the most unique, most challenging, and most cornerstone. Each one requires its own research and development, along with vastly different challenges. I feel writing the actual applications will be a very small part of the project, and moreover some of the advanced specs like filesystems and paging will come later. I think I've actually reached around 50-65%. The Upcoming year In the upcoming year I will focus on presenting my project in a better way and making the most of what I have, to gain the most out of this incredible experience. Stay tuned for updates soon. Refactoring
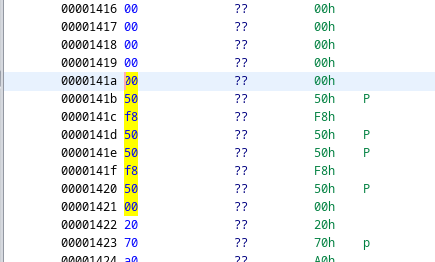
This will be a brief update as most of the time spent this week was doing refactoring of code and adding more documentation in comments. I will include images and demonstrations in a later blog post before the next major one on September 1st. I optimized the makefile to be more general to target all *.asm and *c source files, regardless of the possibility of their existence in certain directories. I also create custom nested file extensions for the makefile to make the process much clearer during compilation and linkage. Speaking of linkage, I created a linker script which I will hopefully expand upon instead of having to supply linker configurations through the command line arguments. This will also help with things down the road like adding a better stack, filesystem, memory management, and other predefined memory locations. In terms of documentation, I'm using doxygen to generate documentation for all my functions and special variables in my codebase. To do this, I need to go through every file and add special comments to my code so doxygen can understand it properly. The IDT Skeleton The IDT, or Interrupt Descriptor Table, is a data structure used in Protected (32 bit) and Long Mode (64 bit) kernels to handle interrupts, both with interfacing with hardware and for traps such as memory faults. I set up the basic IDT code and I will update it in a later blog post. My immediate next step will be implementing the keyboard driver which will only take a day or two. At that point, I can get ready on the final step in my summer goals. A separate update for the IDT will come soon... Exciting Updates To Come and Finishing Off Few features were added but I'm still on track for finishing up for the summer with a rudimentary shell. I'm also working with Mr. Baraty and another mentor to figure out the electronics of my project. I think currently after I create my shell language and possibly include a file system and memory manager I will have completed 70% of the baseline needed software for the entire fellows project. Finally the font problems have all been fixed and sanity has been restored! After debugging for literal weeks and several false revelations, I have finally the fontdriver code to work properly, and I (hopefully) will never have to transition back to BIOS graphics mode 0x3 to debug. Now, as referenced in the title, I can printf and draw symbols to the screen using my own font code. The code will need to be optimized and R E F A C T O R E D many times later on... but this is still a huge step forward. 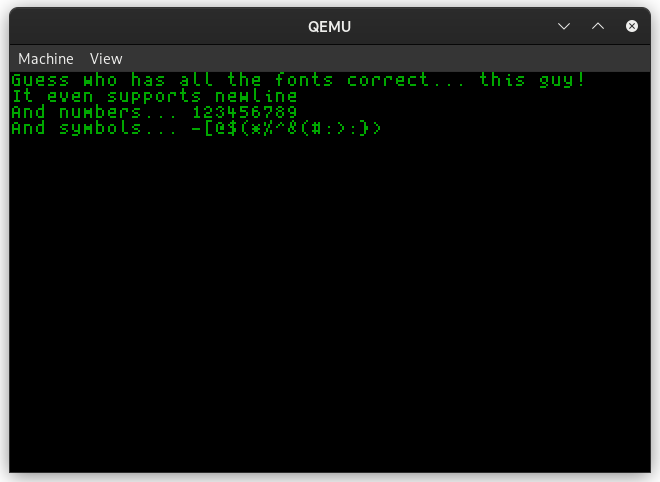  I had to solve a few key bugs. to give a refresher, this is my current (fixed) font specification. Every character is a represented as a bitmap image in an array of bytes. The first line with the fontchar datatype is defined as a byte pointer, which just allows for more liberty in accessing memory. A font contains a width, height, and array of fontchars. Remember that fontchars are simply pointers that point to the location in memory where you have the graphical data. When declaring a new font, the graphical data is already injected in memory, and a simple init function stores pointers (fontchars) in the array upon startup which is then reinterpret-casted to this struct. You might wonder, why not just bypass having pointers and have a gigantic block of data that maps to every fontchar? Well many ASCII characters actually aren't meant to be printed and are rather control codes, like the newline. To make all the data continuous in this alternate scheme would require lots of dummy blocks of zeros or magic numbers. Since we have no filesystem yet, everything is loaded into memory and I don't want this kernel to be b l o a t. Now that we're done refreshing, time for the first bug: First bug: Using lea instead of mov. In the earlier blogpost, I had labels to every block of bytes so I could retreive their memory address and store the pointers in the array. To do this, my init function "mov"s the memory address of the label into the array. However, I used the LEA instruction instead of the MOV instruction. I got confused by the naming and it wasn't until probing the code with gdb and ghidra that I found this utterly unfortunate mistake. 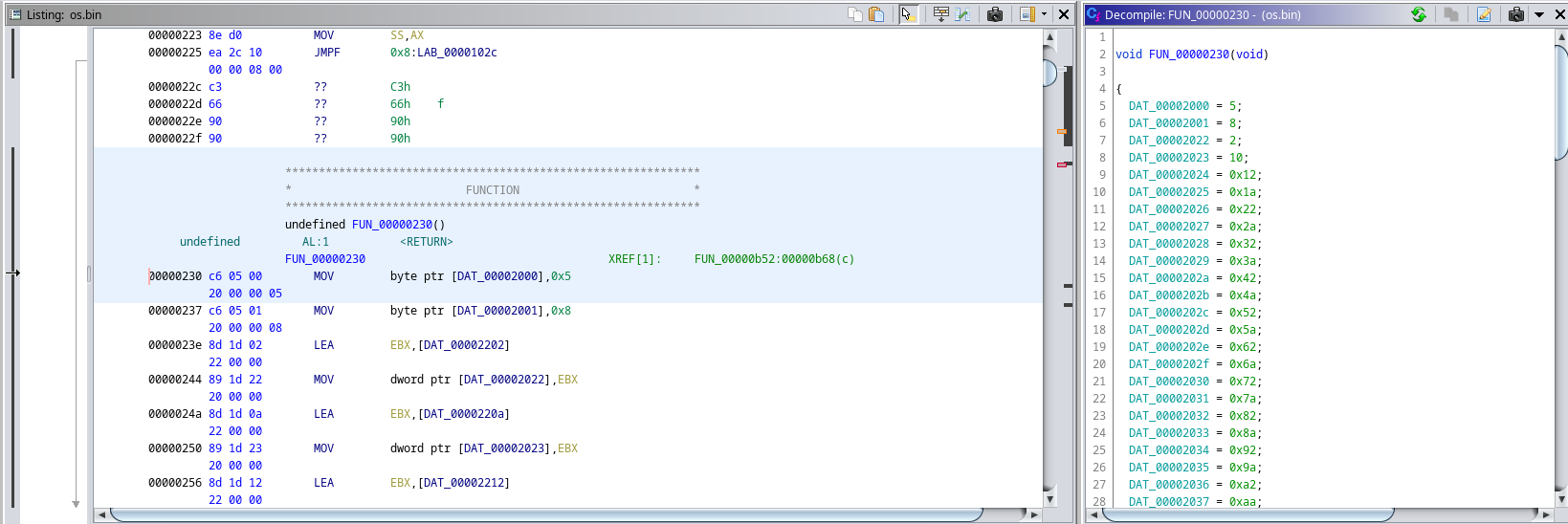 Wait... I'm looking back at the ghidra image... it seems that NASM automatically accounted for the LEA instruction since I wasn't using effective addressing, so it inferred it and put it in. Hmmmmm. Well there's still bugs to come! Second bug: When you forget that in assembly +1 means +1 byte, not +1 on the index. This caused so much trouble and it was such a devious and sneaky problem. After extensively using a combination of GDB, Ghidra, and qemu run flags I was able to pin down that memory was being incorrectly MOV'd. After storing a pointer, the init function doesn't hop over 4 bytes to the next free block of zeros, but rather moves 1 byte and overwrites part of the previous pointer. You can see in address 0x2080 the address is malformed. At first I thought it was endianess but no. Pointers here are expected to be around 0x2000 to 0x2200. If this program were to run in user space it would segfault immediately.
Third bug: movzx confounding me. Reducing eax to all zeros. An incorrect datatype. In the refresher, I mentioned how the fontchar datatype is simply a pointer to bytes in memory. I think because I switched schemes so often I made the array in the font struct fontchar* instead of fontchar. This meant it was an array of pointers to pointers to bytes. An extra recast instruction slipped in. When the bytes were already accessed and stored in a variable, the code mistakenly treated the variable as a pointer to the actual bytes. When testing with 'A', the first 4 bytes are 0x90906000 (little endian in the EAX register). When trying to access the memory address at x90906000, the kernel freaked out and just returned 0. This led to the supposed data being all blank. 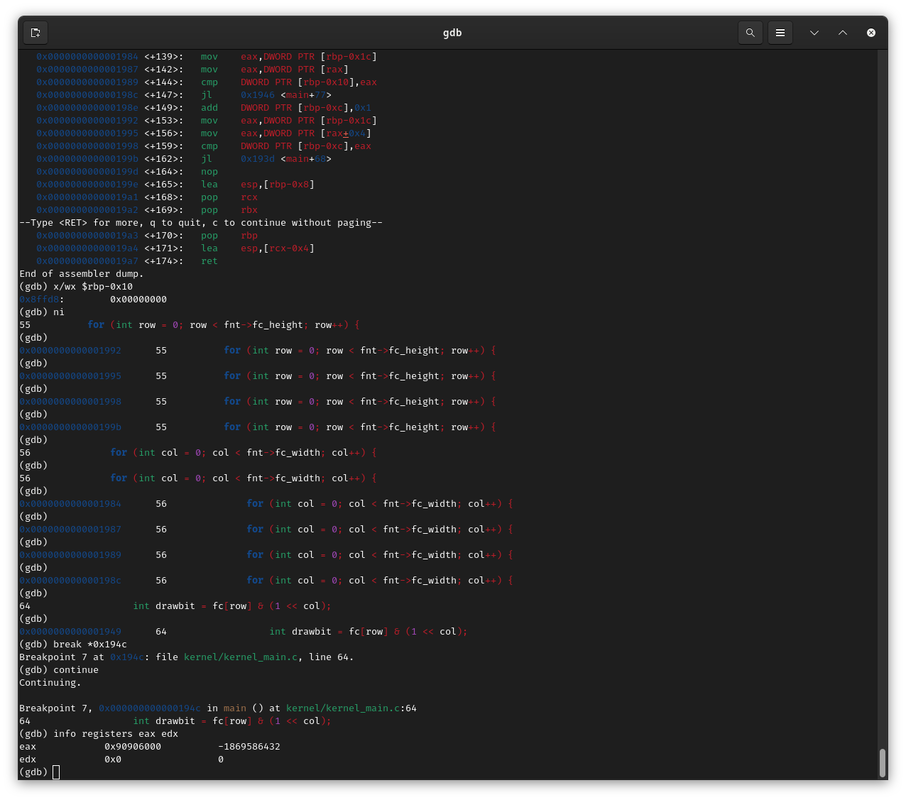 Next step in the shell: Interrupts
Interrupts are already underway. I'm setting up the IDT and ISRs in the same way I'm doing the GDT. Some refactoring will be needed both before and after that to finalize some kernel and toolchain architecture considerations. Be prepared. Once I can use interrupts, user input is possible. Summer goals for the shell: Simple Shell No Turing Completeness When the IDT is completed I can focus on implementing a rudimentary user input system. It won't be much but it's honest work. I'll discuss with my mentors on how to proceed forward and my timeline for the summer goals as I'm starting to reach the end stages. It's not just big– its large.This website is in light mode.
Unacceptable. This website will be converted to dark mode in time for my August 1st update. Stay tuned for the amazing world that is interrupts.  Things are starting to come to a slow but there has been major progress in the font department, among other news. Fonts and Datastructures The journey is long and hard… and C is doing me no favors. After testing many iterations of storing and handling fonts, using scripts, workarounds, etc. I’ve finally found a solution that has gotten me to the next stage of progress. Here is a list of my architecture attempts. Solution 1: Define two types, fontchar, and font. Fontchars will be free-size two-dimensional char arrays, where a space means no pixel and a # means yes pixel. Fonts simply contain an array of pointers to each character and other metadata like kerning, dimensions, etc. A driver can be written to simply scan across each character and decide to put a pixel. Problems:
 Solution 2: Take an already existing font and use a python script to transform it into the same fontchar and font architecture. Problems:
Solution 3: Same as solution 2 but this time design a new architecture and handoff more to my C driver. The new architecture will mirror the BSF font spec and have data in byte arrays. I literally just copy the bitmap representation in the font file, dress it up, and slap a header guard and I’m done. Problems:
Using binary data seems great. It’s very low maintenance in terms of transforming data and it works well with my C code. Writing the bitshift code seems like black magic and also inefficient at the same time. But that’s another topic. I’m currently dealing with a problem where the defined font struct (which is just an array of pointers) has everything at zero for some reason. I’ll use ghidra and gdb to figure what’s happening. Organization After talking to one of my mentors, I am able to see a clearer picture of my big goals and what I need to do to accomplish them. I’m using the strategy to break each goal down into the smallest possible task. That way no matter what I do, I’m always making progress. My mentor used the example of scrum, in how every task for a programmer should be no longer than two weeks. If not, it’s too big. I’m using this philosophy except on a smaller time scale. 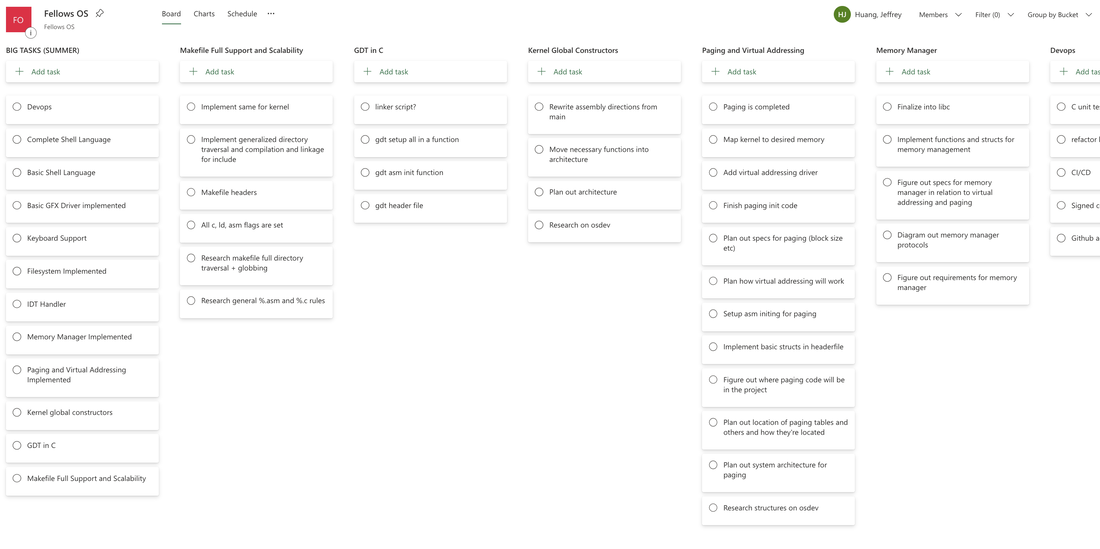 Preview of my initial breakdown.
This is a small update.
Software licenses are hard. Being able to use other peoples' code is one of the beauties of open source. However, most open source repositories have software licenses, which define exactly how the code can be used and/or redistributed. There are a range of licenses you can use, but the problem is that open source licenses won't always be compatible with one another. The license I plan to use for my repository will probably be the GNU GPLv3 License, and the font has the BSD 2-Clause "Simplified" License. After checking with this tool, they should be compatible. Now all I need to do is make my project a GitHub repository, add the licenses, READMEs, etc. and configure git submodules to include the font. I'll probably create myown gh organization to handle all the repo's like my shell language too. Fonts and Implementation Details
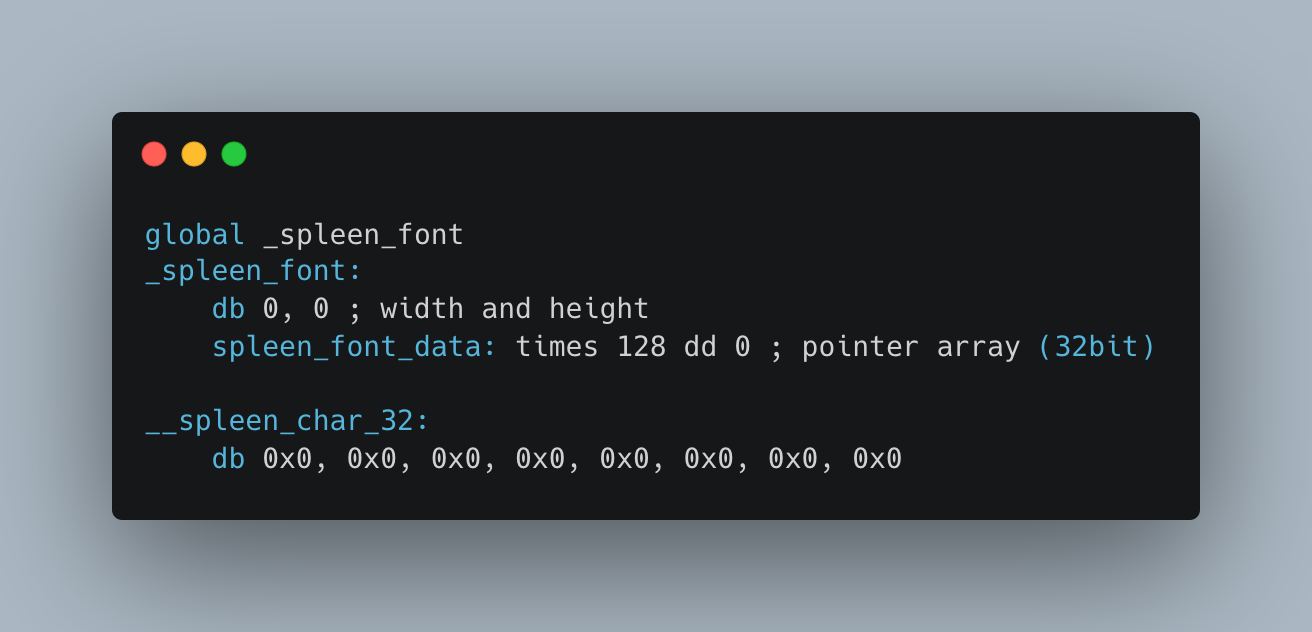
Looking ahead, I knew there were still many challenges before I could get a proper I/O system in place, let alone a tty (TeleTYpewriter or Terminal) or shell. I realized that manually hard-coding in the font characters was going to take too long and wasn’t worth the effort. Even after I kept only the most relevant characters (0x20 to 0x5A plus a few others) and rescaled my bitmap resolution down from 8x8, it was still too much. I instead looked on github for FOSS (Free and Open Source Software) bitmap fonts. The problem was that there were so many file formats, and so many font specifications I had to read before I could understand what I was dealing with. I have to be honest— typography isn’t my strong suit. I eventually found a bitmap font that was simplistic enough for me easily translate into my code. I’ll use python scripting to interpret the necessary information form the font file and output it in source file. I haven’t settled on a font interface/protocol but for now I’ll probably define a font struct which can standardize and map chars to fontchars and create the necessary header and source files. Fontchars will just be 6x8 boolean arrays. You might ask, why can’t I just download the font file and write a font reader driver in c? The problem is I don’t have a working file system. Once I get a file system driver up and preprocessor I can write a proper driver, but this will do for now. Future Goals: IDT Writing the conversion script won’t take too long, and then I can get started on the next big milestone: creating an IDT (Interrupt Descriptor Table). I already mentioned how I can’t use BIOS interrupts to put text to the screen; I also can’t read keyboard input either. To solve this, I’ll have to set up an IDT and write the necesary ISRs (Interrupt Service Routines) to handle everything. After completing this, I’ll probably have to do some more refactoring. Future Goals: TTY and Shell Once I’m able to receive keyboard input, I can start writing the code for a basic terminal. Things like proper text graphics handling will be the first thing. Then I can write rudimentary shell functions like whoami which displays the current username. I don’t have a file system so directory traversal functions like ls or cd won’t be implemented. At least for this stage, there won’t be anything complicated, just a simple switch statement to some functions. Of course, that’s no where near a functioning shell. Aside from the fact I have no file system, I can basically only use one-word commands that just print the same text over and over again. To make a more complex shell, I’ll have to write a language interpreter. It will start pretty simple, just lexing and parsing character by character, keyword by keyword, but my ultimate goal is to have something comparable to bash. Future Goals: Paging, Virtual Addressing, and Memory Management That will… be a problem. I held off on adding paged memory because reading the specification gave me a headache and the structure was too much to take in. Writing a memory manager is already a daunting task in it’s own right, but having to deal with writing handlers for the paging is way more difficult. This is going to be something I’m going to have to deal with very soon. Since now, all my data and buffers have been statically allocated, but sometimes its useful to be able to handle situations you can’t perfectly predict. I already know a bit about writing a programming language, and if I want a shell language as functional as bash, I’ll need to implement an AST (Abstract Syntax Tree). I won’t get too much into the details, but rest assured creating ASTs without a dynamic memory allocator is not something I want to do. Other Future Goals: Filesytem, Mentors, EE I’ll need to create a file system. I’ll probably just implement FAT32 or some other version of FAT. Working out my system architecture will be continuous process. I’m also currently speaking to potential mentors. I’m also going to start research on the boards I need for my EE phase. Makefile Woes
One of the beauties of writing code is that for every one hour spent coding, two are spent debugging and refactoring. Most of this week was spent refactoring and learning the tricks of Makefile, a tool that lets you automate large build projects with a declarative language style. It took me a lot of time figuring out how my project architecture was going to be shaped and how I should manage the compilation for each core part of my OS. Initially there was one Makefile in the top level of my project directory that managed everything. I saw eventually that when adding global constructors I will have to migrate my kernel code to its own directory. This will house the terminal driver, basic VGA graphics driver, and other includes. I also started building out my standard library, creating a folder called libc. This housed the basic functionality like string manipulation, math, and font handling. Fonts Speaking of font handling, I had recently transitioned to using VGA 320x200 256 color graphics. Contrasted from the previous video mode, I can modify individual pixels and their colors, rather than using the builtin text mode. This only required switching my BIOS interrupt call in my bootloader, but I had to make many changes in order to get back to where I was before. I now had to create my own font and write a driver that could display pixels and draw characters. Since I haven’t made much development in my math.h library, I decided to use 8x8 bitmap fonts rather than vector fonts that I’ll have to write a rasterizer for. I implemented the capital letters A, B, C, D, E and I have a working bitmap font renderer. This will definitely need to be altered and refactored as time goes on since I’m still in the very early stages of development and writing a complete graphics driver will span the entire year. I’m working to implement the rest of the letters and hopefully set out on the next steps. One problem I did encounter, however, was mapping. I couldn’t assign a const variable to every ascii character for a variety of reasons
Circling back to Makefile, after I made a Makefile for each core component of my OS, I changed my mind. Now I have a central (more organized) Makefile for my project and the toolchain development timeline is more clear. Moving Forward These will likely be my immediate next steps
I’ll also need to figure out what LICENSE file to use when I inevitable upload this as a git repository to GitHub. I’ll need to talk to my mentors more about that. I’m also still working on gathering all my mentors. I also soon plan to start researching the EE side for parts to include in my device. |
AuthorWrite something about yourself. No need to be fancy, just an overview. Archives
November 2022
Categories |
||||||||

 RSS Feed
RSS Feed

{kind=link}